

Comment fonctionne l’algorithme de X / Twitter ? Comment Twitter (renommé X par Elon Musk) priorise les tweets ayant accès à la Timeline de chaque utilisateur ? Quels sont les critères et facteurs de classement des tweets ? Comment l’algorithme de X / Twitter pondère les signaux d’engagement pour donner de la visibilité (ou non) à votre compte ? Elon Musk l’avait annoncé : X / Twitter a révélé son code source et notamment sa partie algorithme avec à la clé une vue inédite sur ce qui permet à un tweet d’obtenir du reach ou non. Autant de tactiques et bonnes pratiques à appliquer par vous.
Note de Rudy : Si vous êtes expert en marketing, vous pouvez proposer vos articles en me contactant sur la page dédiée.
Avant de débuter votre tutoriel, récupérez mes stratégies pour générer +100 000 visiteurs et des 100aines de prospects et clients chaque mois. Retrouvez les contenus de Webmarketing Conseil / Rudy Viard sur
LinkedIn,
X / Twitter,
Instagram,
YouTube
et
TikTok.
Si vous êtes prestataire, cabinet conseil, agence, consultant, coach ou indépendant, découvrez mon accompagnement pour passer un cap mais aussi mon programme de formation Trafic & Clients mêlant e-learning et coaching de groupe.
L’algorithme de X / Twitter : fonctionnement et historique
A l’origine des réseaux sociaux, le nombre de compte ou amis que chaque utilisateur suivait était relativement limité, l’usage de Facebook ou Twitter en étant à ses balbutiements.
La valeur d’un réseau étant « égale au nombre de ses noeuds à la puissance 2 », l’augmentation du nombre de connexions a permis la démultiplication du nombre de publications circulant sur ces réseaux.
- Si vous êtes seul à disposer d’un smartphone, vous n’appellerez personne (logique).
- Si vous êtes deux à disposer d’un smartphone, vous appellerez régulièrement votre ami.
- Si 90% de vos proches disposent disposent d’un smartphone, il devient un outil central de communication (et potentiellement de votre vie).
L’explosion du nombre de contenus et de posts publiés chaque jour sur Facebook, Twitter ou Instagram a nécessité de repenser l’organisation des fils d’actualité pour 4 raisons :
- Délivrer une expérience personnalisée à chaque utilisateur en poussant les thèmes, contenus et comptes qu’il apprécie.
- Donner plus d’écho aux « meilleures » publications pour augmenter le temps passé sur la plateforme (et augmenter les revenus publicitaires).
- En miroir, rendre silencieux les contenus non désirés (selon les priorités de chaque plateforme).
- Laisser de la place à la publicité (et donner une bonne raison aux annonceurs de payer pour obtenir de la visibilité).
A ce titre, Twitter a longtemps résisté à l’appel des algorithme en conservant son classement purement chronologique qui était l’ADN de la plateforme à ses débuts (preuve que la mise en place d’algorithmes de classement par l’engagement n’était pas un chemin obligatoire) mais, non sans scandale, les algorithmes ont commencé à pondérer l’apparition ou non des tweets dans vos fils d’actualité.
Cette modification date sauf erreur de ma part de 2016 avec l’apparition d’une option « Show me the best tweets first » qui laissait alors la main à l’utilisateur entre l’ordre chronologie et un classement algorithmique. Jusqu’à évidemment l’extension de cette fonction à l’ensemble des tweets.
Globalement, ce que l’on savait sans forcément avoir de données sur ces facteurs de classement :
- L’engagement sur vos tweets impacte votre portée (votre reach en anglais donc la portée de vos publications).
- La visibilité de vos tweets démarre par votre premier cercle (vos followers les plus actifs).
- Si vous ne passez pas les filtres, vos tweets ne sont pas diffusés (ou peu diffusés).
- Si vous passez votre premier cercle avec un fort engagement, votre tweet pourra être diffusé à de nouveaux utilisateurs.
- Jusqu’à lentement mourir et que de nouveaux tweets plus engageants viennent prendre la place de votre contenu.
Plongeons maintenant dans les nouvelles données officielles et/ou issues directement de l’étude du code pour confirmer ou infirmer ce feeling.


L’algorithme de recommandation de X / Twitter
Regardons d’abord ce que l’on apprend du côté de l’annonce officielle de X / Twitter (nous verrons ensuite ce que l’analyse du code source montre de nouveau et que vous ne trouverez pas dans le communiqué officiel).
Je vous donne en français de ce communiqué publié sur le blog de X :
X / Twitter vise à vous offrir le meilleur de ce qui se passe dans le monde en ce moment. Cela nécessite un algorithme de recommandation pour distiller les environ 500 millions de Tweets publiés quotidiennement jusqu’à une poignée de Tweets les plus importants qui apparaissent finalement sur la chronologie « Pour vous » de votre appareil.
Comment choisissons-nous les Tweets ?
La base des recommandations de X / Twitter repose sur un ensemble de modèles et de fonctionnalités essentiels qui extraient des informations latentes à partir des données de Tweet, d’utilisateur et d’engagement.
Ces modèles visent à répondre à des questions importantes concernant le réseau X, telles que : « Quelle est la probabilité que vous interagissiez avec un autre utilisateur à l’avenir ? » ou « Quelles sont les communautés sur X et quels sont les Tweets tendances au sein de celles-ci ? ». Répondre à ces questions avec précision permet à X de proposer des recommandations plus pertinentes.
Le pipeline de recommandation est composé de trois étapes principales qui utilisent ces fonctionnalités :
- Récupérer les meilleurs Tweets provenant de différentes sources de recommandation dans un processus appelé « sourcing des candidats ».
- Classer chaque Tweet à l’aide d’un modèle d’apprentissage automatique.
- Appliquer des heuristiques et des filtres, tels que la suppression des Tweets provenant des utilisateurs que vous avez bloqués, des contenus inappropriés et des Tweets que vous avez déjà vus.
Le service responsable de la construction et de la diffusion de la chronologie « Pour vous » s’appelle Home Mixer. Home Mixer est basé sur Product Mixer, notre framework Scala personnalisé qui facilite la création de flux de contenu. Ce service agit comme la colonne vertébrale logicielle qui relie différentes sources de candidats, fonctions de notation, heuristiques et filtres.
Le schéma ci-dessous illustre les principaux composants utilisés pour construire une chronologie :


Explorons les principales parties de ce système, dans l’ordre approximatif dans lequel elles seraient appelées lors d’une seule demande de chronologie, en commençant par la récupération des candidats à partir des sources de candidats.
Sources de candidats
X / Twitter dispose de plusieurs sources de candidats que nous utilisons pour récupérer des Tweets récents et pertinents pour un utilisateur. Pour chaque demande, nous essayons d’extraire les 1500 meilleurs Tweets d’un ensemble de plusieurs centaines de millions grâce à ces sources. Nous trouvons des candidats parmi les personnes que vous suivez (« In-Network ») et parmi les personnes que vous ne suivez pas (« Out-of-Network »).
Aujourd’hui, la chronologie « Pour vous » (« For you ») se compose en moyenne de 50% de Tweets « dans le réseau » et de 50% de Tweets « hors du réseau », bien que cela puisse varier d’un utilisateur à l’autre.
In-Network Source (sources « dans le réseau »)
La source « dans le réseau » est la plus grande source de candidats et vise à fournir les Tweets les plus pertinents et récents des utilisateurs que vous suivez. Elle classe efficacement les Tweets de ceux que vous suivez en fonction de leur pertinence à l’aide d’un modèle de régression logistique. Les meilleurs Tweets sont ensuite envoyés à l’étape suivante.
Le composant le plus important dans le classement des Tweets « dans le réseau » est Real Graph. Real Graph est un modèle qui prédit la probabilité d’engagement entre deux utilisateurs. Plus le score Real Graph entre vous et l’auteur du Tweet est élevé, plus nous inclurons leurs tweets.
La source « dans le réseau » a fait l’objet de travaux récents chez X. Nous avons récemment cessé d’utiliser Fanout Service, un service de 12 ans qui était auparavant utilisé pour fournir des Tweets « dans le réseau » à partir d’un cache de Tweets pour chaque utilisateur. Nous sommes également en train de repenser le modèle de classement par régression logistique qui a été mis à jour et entraîné pour la dernière fois il y a plusieurs années !
Out-of-Network Sources (sources « hors du réseau »)
Trouver des Tweets pertinents en dehors du réseau d’un utilisateur est un problème plus délicat : comment pouvons-nous savoir si un certain Tweet vous sera pertinent si vous ne suivez pas l’auteur ? X adopte deux approches pour résoudre ce problème.
Graph social
Notre première approche consiste à estimer ce que vous trouveriez pertinent en analysant les engagements des personnes que vous suivez ou de celles ayant des intérêts similaires.
Nous parcourons le graphe des engagements et des abonnements pour répondre aux questions suivantes :
Quels Tweets les personnes que je suis ont-elles récemment appréciés ?
Qui aime des Tweets similaires à moi, et qu’ont-ils récemment aimé d’autre ?
Nous générons des Tweets candidats en fonction des réponses à ces questions et classons les Tweets résultants à l’aide d’un modèle de régression logistique. Les parcours de graphes de ce type sont essentiels à nos recommandations « hors du réseau ». Nous avons développé GraphJet, un moteur de traitement de graphes qui maintient un graphe d’interaction en temps réel entre les utilisateurs et les Tweets, pour exécuter ces parcours. Bien que ces heuristiques pour rechercher le réseau d’engagement et de suivi
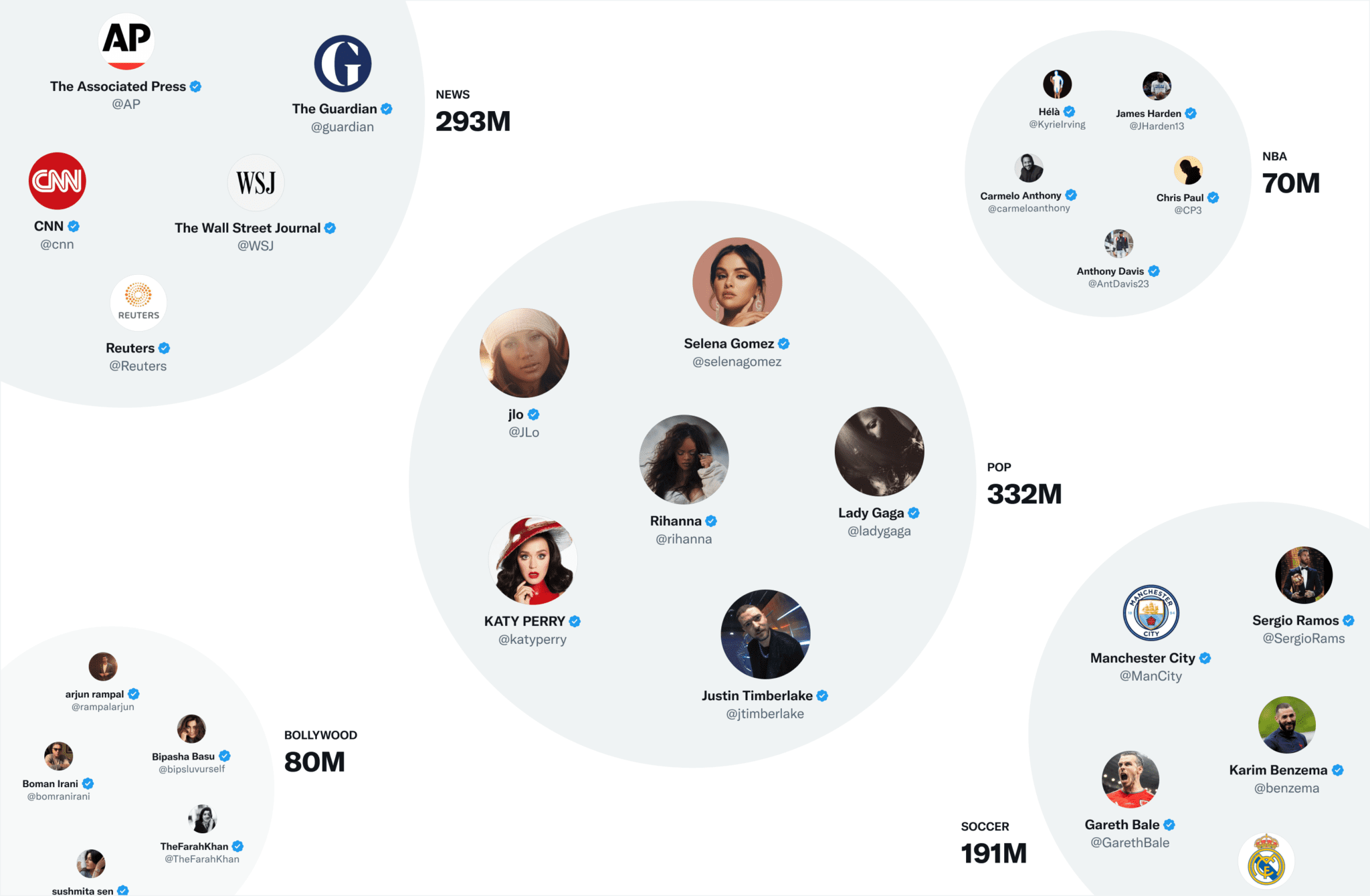

Nous pouvons intégrer des Tweets dans ces communautés en examinant la popularité actuelle d’un Tweet dans chaque communauté. Plus les utilisateurs d’une communauté aiment un Tweet, plus ce Tweet sera associé à cette communauté.
Classement
L’objectif de la chronologie « Pour vous » est de vous proposer des Tweets pertinents. À ce stade du pipeline, nous avons environ 1500 candidats qui pourraient être pertinents. Le score prédit directement la pertinence de chaque Tweet candidat et constitue le principal signal de classement des Tweets sur votre chronologie. À cette étape, tous les candidats sont traités de manière égale, sans tenir compte de la source du candidat d’origine.
Le classement est obtenu avec un réseau neuronal d’environ 48 millions de paramètres qui est continuellement entraîné sur les interactions de Tweets pour optimiser l’engagement positif (par exemple, les mentions J’aime, les Retweets et les Réponses). Ce mécanisme de classement prend en compte des milliers de caractéristiques et génère dix étiquettes pour attribuer un score à chaque Tweet, chaque étiquette représentant la probabilité d’un engagement. Nous classons les Tweets à partir de ces scores.
Heuristiques, filtres et fonctionnalités du produit
Après l’étape de classement, nous appliquons des heuristiques et des filtres pour mettre en œuvre diverses fonctionnalités du produit. Ces fonctionnalités fonctionnent ensemble pour créer un flux équilibré et diversifié.
Voici quelques exemples :
– Filtrage de visibilité : Filtrer les Tweets en fonction de leur contenu et de vos préférences. Par exemple, supprimer les Tweets des comptes que vous bloquez ou mettez en sourdine.
– Diversité des auteurs : Éviter trop de Tweets consécutifs d’un seul auteur.
– Équilibre du contenu : Veiller à ce que nous offrions un équilibre équitable entre les Tweets du réseau et hors réseau.
– Fatigue basée sur les commentaires : Diminuer le score de certains Tweets si l’utilisateur a fourni un retour négatif à leur sujet.
– Preuve sociale : Exclure les Tweets hors réseau sans connexion au deuxième degré avec le Tweet comme mesure de qualité. En d’autres termes, s’assurer que quelqu’un que vous suivez a interagi avec le Tweet ou suit l’auteur du Tweet.
– Conversations : Fournir plus de contexte à une réponse en la reliant au Tweet original.
– Tweets modifiés : Déterminer si les Tweets actuellement sur un appareil sont obsolètes et envoyer des instructions pour les remplacer par les versions modifiées.
Mélange et diffusion
À ce stade, Home Mixer a un ensemble de Tweets prêts à être envoyés à votre appareil. Dans la dernière étape du processus, le système mélange les Tweets avec d’autres contenus non-Tweet tels que les publicités, les recommandations de suivi et les invites d’intégration, qui sont renvoyés à votre appareil pour être affichés.
Le pipeline ci-dessus fonctionne environ 5 milliards de fois par jour et se termine en moins de 1,5 seconde en moyenne. Une seule exécution du pipeline nécessite 220 secondes de temps CPU, soit près de 150 fois la latence que vous percevez sur l’application.

Analyse du code source de X / Twitter et bonnes pratiques
Le post de X / Twitter est en soi extrêmement intéressant en tant qu’il donne une vue de l’intérieur de l’algo de X expliqué par X.
Mais vu que le code source est maintenant disponible en accès libre en ligne (ici et ici), nous pouvons également l’étudier avec un œil neutre.
Je ne suis pas développeur (même si j’aurais pu utiliser ChatGPT pour m’expliquer le code) mais plusieurs utilisateurs de X (notamment @aakashg0, @steventey ou encore nft_god entre autres) ont fait le job et voici ce qu’ils ont découvert :
1. L’impact des J’aime / Likes, Retweets & Réponses / Replies
X détermine votre influence dans le réseau en analysant un ensemble de facteurs et vous assigne un score appelé « Tweepcred ». Ce score impacte ensuite le score individuels de vos tweets (donc si Elon Musk tweete une banalités, ce tweet ira plus loin que s’il vient de vous ou de moi).
En analysant le code source, voici ce que l’on découvre sur les critères d’engagement et leur pondération dans les scores de classement :
1. Chaque like / j’aime donne un score de 30
2. Chaque retweet donne une score de 20
3. Chaque « reply / réponse » ajoute seulement 1 à votre score
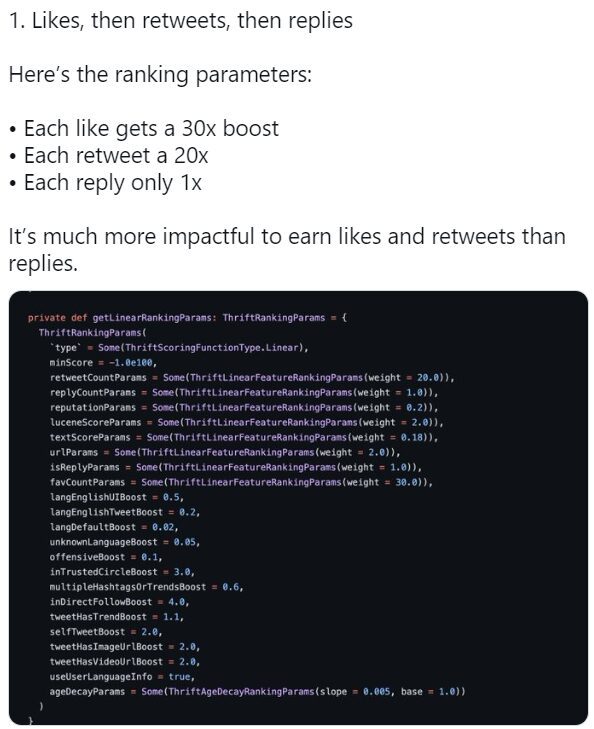

Résultat : les likes sont (étonnamment) les plus impactants (et pas forcément les discussions et commentaires sous le tweet).
2. L’impact des contenus images et vidéos
L’ajout d’une image ou d’une vidéo à votre tweet (outre que ces contenus peuvent rendre plus visible votre tweet en prenant plus de place dans la Timeline ou simplement enrichir votre tweet, une image ou une vidéo pouvant capter l’attention au milieu de tweets sous forme de textes), permet « organiquement » d’obtenir un boost dans les classements.
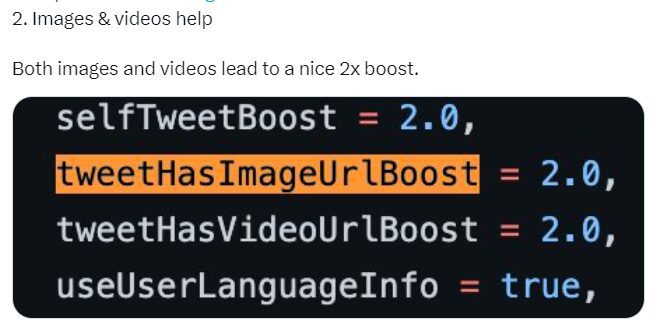

Résultat : ajoutez des images et vidéos pour bénéficier de ce boost dans les ranking.
3. L’impact des hashtags
L’ajout de hashtags multiples (plus d’un) vous déférence quasiment automatiquement.
N’utilisez pas (ou peu) de hashtags.
4. L’impact (négatif) des liens externes
L’ajout d’un lien externe (vers une source tierce hors de X / Twitter) à votre tweet pénalise votre publication. Les posts qui font « sortir » l’utilisateur de la plateforme sont une perte de revenus publicitaire pour X.
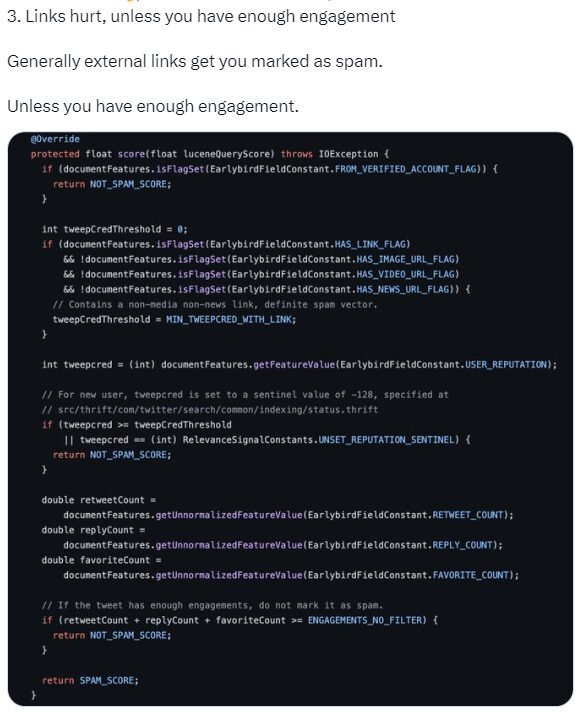

Résultat : restez sur la plateforme sans quoi le tweet sera marqué comme un « spam » et nettement minoré.
5. L’impact de votre ratio followers / following
Le nombre de vos followers est important mais le ratio entre ce nombre d’abonnés (followers) et les comptes que vous suivez (following) est également critique. Donc ne suivez pas trop de comptes dans l’espoir d’être repéré (ou en automatique), cela vous pénalise.


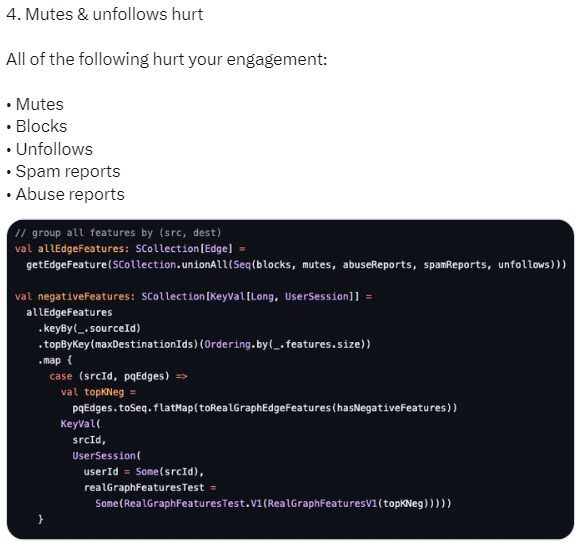
6. L’impact des « mute » et « unfollow »
Comme décrit dans le post officiel de X, les tweets « mis sous silence », « bloqués », « unfollowés », « mis en spam » ou en « report abuse » sont logiquement pénalisés.

7. L’impact du badge « X Blue »
Aucune surprise, si vous avez le badge « X Blue » (et que vous payez donc), vos tweets bénéficieront d’un boost « au sein de votre réseau » mais également « hors de votre réseau ».
![]()

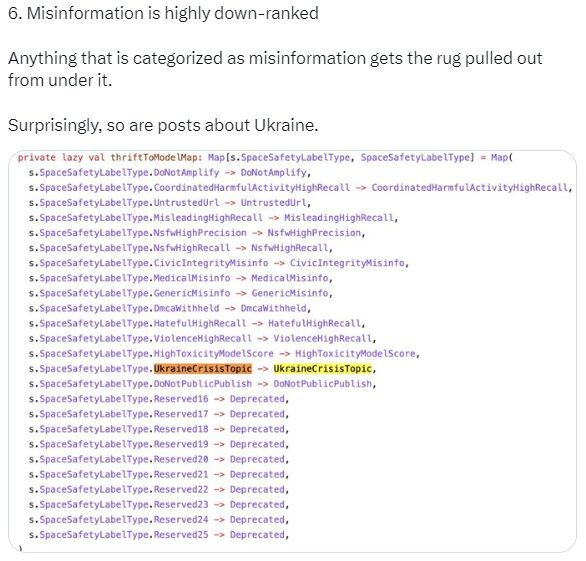
8. L’impact de la désinformation (fake news & spambots)
Vos tweets s’ils sont flaggés comme fake sur des sujets monitorés par X seront descendus dans les classements et possiblement « shadowban ».

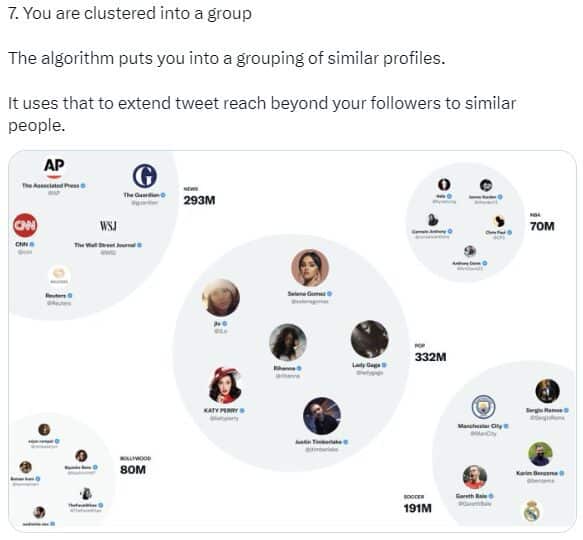
9. L’impact du social graph
La notion de « In-Network » et de « Out-of-Network » est nouvelle : chaque compte est clustérisé dans un groupe de profils similaires. Vos tweets sont d’abord diffusés dans ce groupe proche avant (éventuellement) d’être envoyé plus largement auprès d’une cible plus large.

10. L’impact des clusters « In-Network » et « Out-of-Network »
Vos tweets sont de manière « organique » pénalisés dès qu’ils sont diffusés « hors de votre réseau ».
Cela signifie :
1. Que vos tweets sont d’abord diffusés au cluster où vous avez été filtré (sans pénalité).
2. Qu’en fonction de l’engagement, votre tweet sera proposé « hors de votre réseau » (mais avec une pénalité).
3. Donc que vos tweets qui n’obtiennent pas de likes et de retweets « dans votre réseau » n’ont aucune chance « hors du réseau »
4. Donc que si vous postez sur des thématiques qui n’intéressent pas votre cluster (exemple : vous parlez constamment de marketing et subitement vous parlez de cuisine), votre tweet ne passera pas cette première barrière.
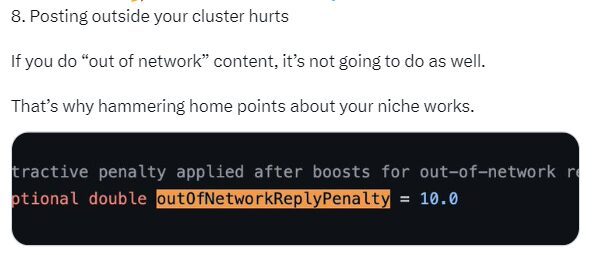

Résultat : restez niché sur une thématique.
11. L’impact de l’orthographe et du vocabulaire
Si vous écrivez avec les pieds, vous serez pénalisé.


12. L’impact du timing (et de l’ancienneté du tweet)
Même si votre tweet est génial, l’algorithme de X / Twitter va lentement le faire disparaître à mesure qu’il date afin de faire émerger des tweets plus récents. Apparemment en faisant baisser le score d’âge de 50% toute les 6 heures. C’est donc à sa publication que votre tweet doit performer pour avoir une chance de s’extraire de la pesanteur terrestre et voler de ses propres ailes.

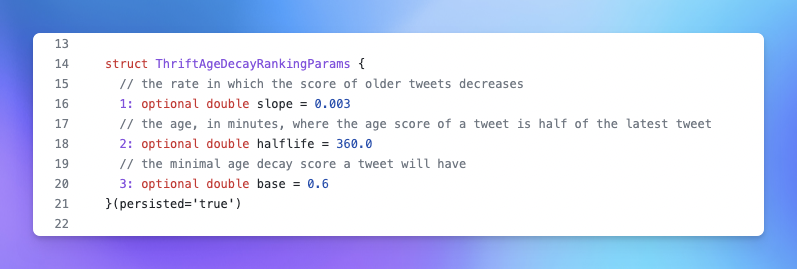
Les 3 signaux qui impactent votre score de pertinence
L’accès à la Timeline et au fil d’actualité des utilisateurs est donc centré autour de 3 agrégations de données :
– Vos données d’engagement (likes, retweets, réponses…)
– Vos données d’utilisateurs (spam, unfollow, mute…)
– Vos connexions (social graph, cluster, followers et donc communauté…)
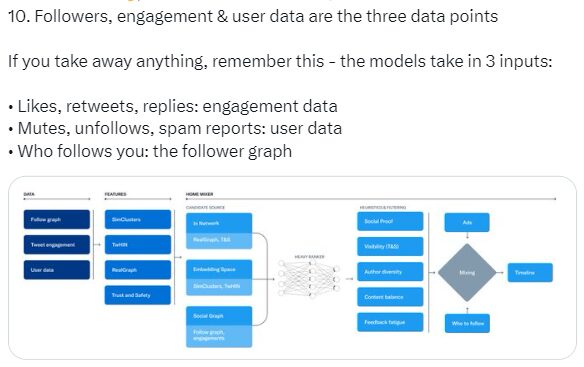

Nous connaissions par expérience une bonne partie de ces éléments mais il s’agit de la première fois que nous obtenons une vue de l’intérieur basée sur non pas des hypothèses mais des données.
J’espère que vous en profiterez pour piocher quelques bonnes idées pour améliorer votre stratégie de contenus.
Développer vos réseaux sociaux est un volet majeur de mes accompagnements pour les prestataires de services, cabinets conseils, agences, consultants, coachs et indépendants qui souhaitent passer un cap ou débloquer leur situation mais aussi de mon programme de formation Trafic & Clients mêlant e-learning et coaching de groupe.